
 2026年03月13日
2026年03月13日当单点算力亟需聚合为集群智能,我们面临的不仅是软件算法的革新,更是底层硬件互联的深度重构。传统电互联的三大痛点,推动全光Scale up成为突破算力瓶颈的关键路径。从“电”向“光”演进的技术必然性与商业经济性,正是光子算数作为行业先行者,在技术演进、产品迭代与商业化落地的最佳印证。
| 电互联遇 “互联墙” 瓶颈,光互联成破局关键
当前,高速铜缆的主流速率正从112G向224G加速迭代,铜导线趋肤效应的掣肘日益明显。铜缆天然存在趋肤效应,当频率增大时,电流越倾向于在导体表面流动致使中心区域电流比较小,导致有效导电截面积变小、交流电阻变大、信号衰减急剧增加。从物理层面看,铜导线与电子传输性能已逼近天花板,即“互联墙”,电互联在带宽、功耗、传输距离的综合指标上已较难实现突破。未来将进一步演进至448G,与此同时将面临严峻的传输损耗攀升问题。
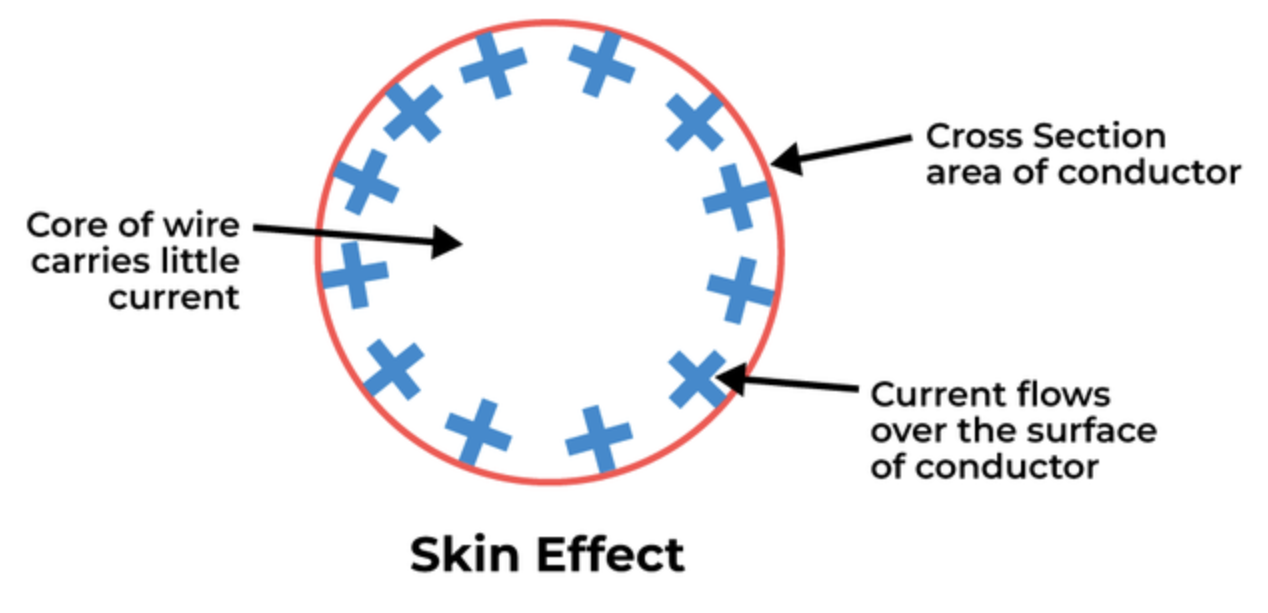
▲导体中存在趋肤效应,来源:Geeks for Geeks
光纤以光信号为传输载体,从根本上规避了电传输的趋肤效应,天然具备打破 “互联墙” 的能力。光互联以“光子”为信息载体,具备高频、低损耗、无电磁干扰等优势,能够突破“速率墙”、“距离墙”和“能耗墙”的限制。
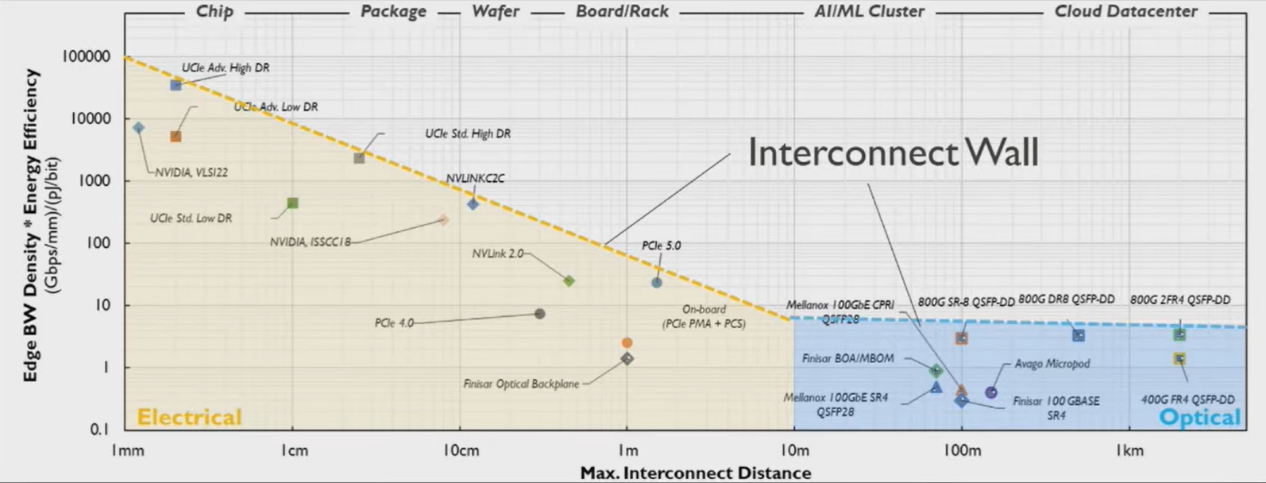
▲电互联面临“互联墙”限制,来源:IMEC,GlobalFoundries
| 单节点内XPU 互联量攀升,多机架布局催生光互联需求
当前<100个XPU互联是典型的Scale up形式,铜缆可很好地适配从Compute Tray到Compute Rack的互联需求。在Compute Tray(<10个XPU)中,无源铜缆连接计算元件和交换机,具备低功耗、低成本优势。在Compute Rack(<100个XPU)中,机架内部的服务器通过铜缆连接,高效、低功耗、低成本但传输距离有限,当数据速率提升至200 Gbps时,由于铜缆的物理极限,链路无法覆盖机架的整个范围。

▲当前Scale up互联情况,来源:MarvellScale up
向多机架超级服务器演进(>100个XPU),传输距离更长的光互联将逐步取代铜互联。随着单节点内XPU互联数量持续攀升,单机架可容纳的XPU数量和算力已难以满足需求,算力扩展必然向多机架架构演进,以聚合更多单节点算力资源,实现跨机架的资源共享和协同计算,提高整体系统的资源利用率和计算效率。在此背景下,多机架模式也对传输距离提出了更高要求,具备更长传输能力的光互联技术因而成为理想的替代方案。

▲Scale up将向多机架超级服务器演进,来源:Marvell
| 单节点XPU规模快速扩张使网络架构承压,光互联兼具性能与成本优势
在单节点XPU规模快速扩张背景下,传统电互联架构已出现明显性能天花板,只有向低损耗、高密度、低时延的光互联演进,才能真正支撑下一代算力集群的网络压力。根据阿里云对基于Switch交换架构的成本分析,在不同规模下互联方案的经济性呈现明显差异。
铜缆覆盖范围内(64或128 XPU),铜缆方案的整体成本大约是光互联方案整体成本的1/2(按照互联成本+Switch成本的综合),铜缆方案占优。
超过铜缆覆盖范围的场景(>128 XPU),采用传统单层光互联方案要比2层(铜+光)方案的成本更低,单层光互联方案占优。
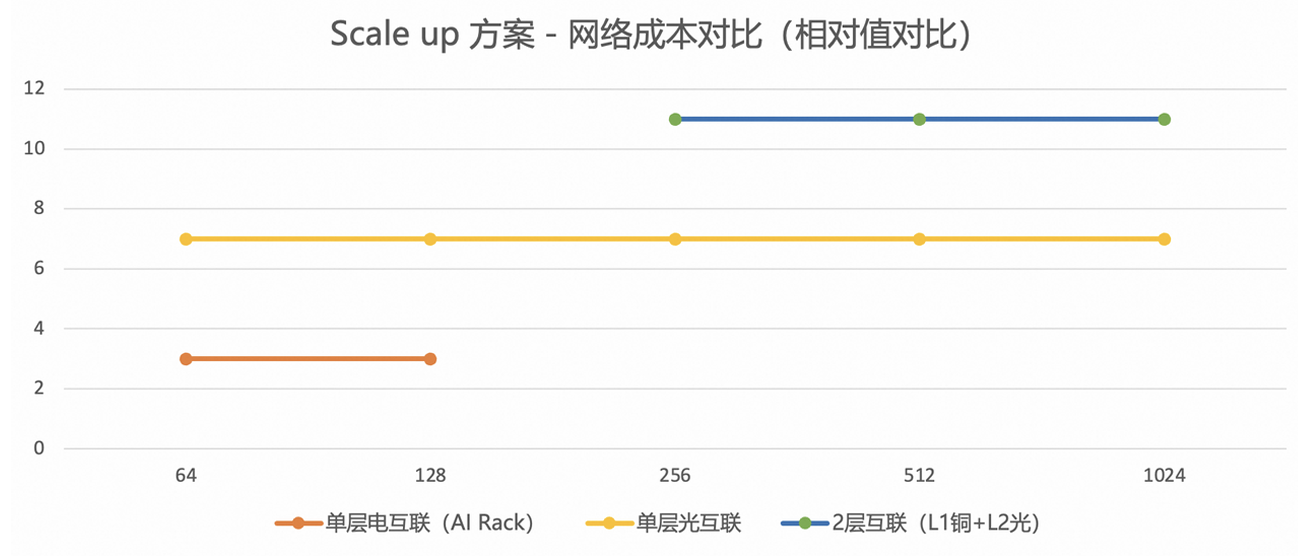
▲来源:UPN512技术架构白皮书v1.0
因此,在规模化扩展的驱动下,光互联不仅突破电互联的性能限制,也在一定规模以上体现出经济性竞争力。
| 光子算数以光直连超节点系统落地,实现产业破局
产业的技术趋势,终将落地为企业的实践。作为作光互联算力集群解决方案先行者,为光子算数创立即锚定“光互联”赛道,不仅洞察趋势,更凭借“硬、网、软”三位一体的自研技术体系,将技术蓝图转化为可部署、可验证的商业化产品。

▲光子算数研发的PhotonFlare光直连超节点系统
目前,公司的PhotonFlare I 光直连超节点系统已实现量产与商用部署,在QWen2.5-72B模型测试中,平均性能提升近2.5倍,有力验证了光互联在大规模算力集群中的核心价值。立足于第一代光直连超节点系统的基础,光子算数正在进行全光互联超节点的研发,同步推动产品的迭代升级。
未来,光子算数将依托领先的光互联核心技术、自主可控的产品体系、开放共赢的产业生态,为客户打造更大规模和成本优势的光互联算力集群解决方案。

